
最近操作上碰到了困境,迴歸現象。如同擲硬幣,有時會出現連續正面,但最終會趨近於50%。但操作上比較複雜畢竟不是只有正反這麼單純,還有幅度,更機車的是不正不反的盤整…。在書店漫無目的翻書,突然在本書翻閱時看到-迴歸分析!喔~這不就是我的問題點嗎?當下就甩三張國父,希望本書給我更深入的處理方法。
隨記:
P.16 本書所談論的統計學,全都是為了洞悉人類心理以略微改善其行為及做法的類型。→呃,有點想拿回三張國父了。感覺找錯書。
P.17 統計學依目的可分三大類:1.洞悉人類行為的因果關係。2.掌握現況。3.預測未來。→本書著重洞悉人類行為的因果關係。說白點就是商業銷售方面的統計學(我看完才知道)
P.41 平均值、中位數(median)、眾數(mode)


P.56 支撐著現代統計學的「中央極限定理」:而且不是「許多資料都遵循常態分佈」,就算原始資料未遵循常態分佈,「其中幾筆資料的總和值」也通常會收斂於常態分佈。這種現像稱為中央極限定理。→作者用男女身高作例子,兩組資料混合後會出現雙峰,但隨機抽4筆作統計會出現常態分佈,這現象稱為中央極限定理。


P.56 所謂收斂,就是隨著資料量增加而逐漸趨近,當有無限多的資料時,便會完全一致的概念。
P.77 「偏差的平方和」會隨著資料量增加而變大,即使是變動範相同的資料,也會自然產生這種現象。若是如此,那就別用「偏差的平方和」,改用「偏差的平方平均值」來代表資料的變動範圍即可,而這種就是「變異數」的基本概念。→為什麼不用絕對值,一定要遶一圈平方再回來?這樣就省了一個叫變異數的鬼東西,直接跳進標準差。為什麼書上沒解釋?
P.79 將變異數開根號所求出的值,就名為標準差。其英文是standard deviation 經常縮寫為SD。
P.79 標準差(SD)只單純代表「標準的、與平均值之間的偏差」之意。
P.84 俄國數學家切比雪夫還證明了不論資料的變動狀況如何,平均值-2SD(標準差的兩倍)~平均值+2SD的範圍內,都一定包含全體的4分之3以上的資料。這樣的關聯性稱為「切比雪夫不等式」,它在中央極限定理的證明上亦扮演了相當重要的角色。→這個4分之3實在太重要了,代表著我得放棄75%的機會,選擇權sell side 靠這中央極限定理賺錢,所以我要做 buy side我得盡可能的放棄機會再用累加法堆高buy side 勝率到達臨界點再出手。這概念結合了統計學的中央極限定理和非對稱式交易思維,看來在金融交易我擁有一些天份上的優勢!再給我多些時間、金錢和書籍,我將能征服股市!!
P.90 所謂的統計檢定力就是「當存在某種差距的假設真正成立時,可確實稱之為顯著性差異的機率」
P.91 「明明沒什麼差異,卻視為有差異」的錯誤被稱為第一型錯誤(Type I error)→日本稱α錯誤,或諧音「急驚風」
P.91 「真的有差異,但卻沒找出來」的錯誤稱為第二型錯誤(Type II error)→日本稱β錯誤,或諧音「慢郎中」
P.93像這種5%或1%…等,對第一型錯誤的容許標準,就稱為顯著水準(level of significance)。
P.93 接下來,再想辦法於顯著水準範圍內將「慢郎中之過(第二型錯誤)降至最低或是將檢定力最大化(增加樣本數量最有效)。像這種用不判別假設正確與否的方法,一般在統計學上則稱為檢定(或是統計假設檢定)。
P.99 用來表示從有限資料所求得之平均值及比例有多少機率會與「真值」產生多大稱度的偏離-這正是統計學對誤差的定義。→作者舉樣本數4筆與1000筆為例,兩個樣本各更改一個結果,分別造成25%與0.1的偏離,很明顯樣本數太少,誤差率會高到嚇人。
P.100 資料的變動性越大,平均值偏離範圍就越大。
P.103 很容易與標準差搞混的標準誤差(英文為Standard Error,常縮寫成SE)。
P.103 平均值的標準誤差(SE)→是指樣本平均數的「標準差(SD)」

真想罵髒話,書上解說的沒句看得懂。用圖2-5來猜原意。關鍵字[每次抽出4人並計算],這樣看來,樣本平均數就是指[每次抽出4人並計算]這數值所出現的標準差(SD),稱之為標準誤差(SE)。

P.105 標準差(SD)則是代表原始資料本身的變動狀況的指標。
P.105 多筆資料求出之平均值的變動狀況(標準誤差-SE),一定小於原始資料的變動狀況(標準差-SD)。此外,當用於求值的資料筆數越多(亦即樣本數越多),標準誤差就越小。
P.109 「從資料求得之平均值±2SE」,有時也稱為平均值的95%信賴區間。
P.117 在欲主張「烏鴉基本上都是黑的」這種假設,故意先檢驗「完全顛覆自身主張之假設」,亦即「烏鴉有一半是黑的,一半不是黑的」這類假設,稱為零假設(null hypothesis,或虛無假設)。也就是把自己想主張的事「歸零、歸於虛無」的假設。
P.117 而在假定,零假設成立的狀態下,可從實際或更多其他資料得到反零假設之資料的機率,則叫做P值。P源自表示機率之意的probability這個字。以烏鴉的例子來說,從「假設烏鴉有一半是黑的,一半不是黑的時,連續100次看到黑色烏鴉」這一觀察結果,算出的比例(0.5的100次方)1兆分之1還小的機率,便是P值。P值越小,就越表示「該零假設是不可能成立的」。
P.119 最常做為零假設使用的,大約就是「烏鴉有一半黑,一半不是黑的」這種完全否定自身主張的假設,但也不是不能使用別種假設「黑色烏鴉佔九成」也是很好的零假脫。→感覺假設一半一半比較符合完全否定自身主張的假設意涵。
P.119 信賴區間用平均值±2SE來表示,只是因為算法剛好,但信賴區間的原本意是指「不可能成立的零假設」與「無法完全否定的零假設」其界限是從哪裡到哪裡,而這範圍就是耶日.奈曼(Jerzy Neyman)等人所定義的信賴區間。
--以下書本內容,我已進入迷離狀態。--
P.142 用於處理大量資料的z檢定可能不適合應用在僅20筆資料上,但針對數千筆資料使用t檢定卻絕對沒問題(在這種情況下,使用兩種檢定的結果一致)。因此,要檢驗平均值之差距時,「基本上就選t檢定」。
P.143 z檢定與t檢定的基本想法是一致的,兩者都必須求出p值,而這個p值代表「平均值之差距」為「平均值之差距的標準誤差」幾倍值,是多麼不可能出現的機率。只不過,z檢定用的是距離資料分佈中央±2SE以上的機率為5%的常態分佈,但數量僅幾十筆的資料並不會那麼貼近「常態分佈」。→ 看完這句話如果跟我一樣是正常人,應該也茫了。
P.144 卡方分佈,便能算出以不同資料量算出的不同變異數,與真正變異數之間的差異程度分佈狀況。
P.144 所謂的卡方分佈,是指當變數x遵循平均值為0,變異數為1(亦即標準差也是1)之常態分佈時,此變數之多個平方值加總會遵循的一種分佈(如圖2-15)。
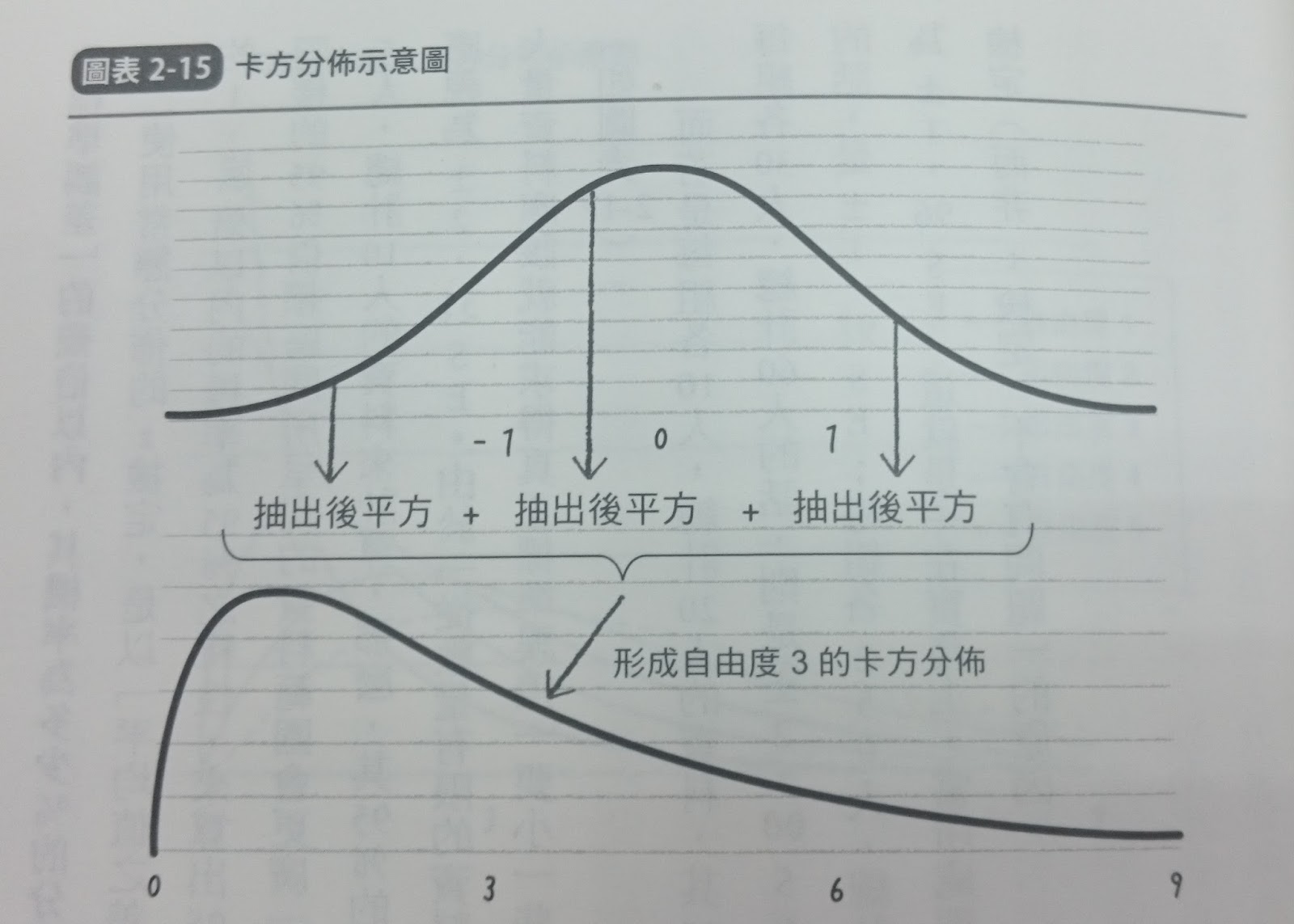
你看懂了嗎?我茫了。

我想問:統計老師這自由度是啥?為什麼我對這張圖沒印象!?這時知道網路不能用本名的真意了,別讓教過的老師認出你。他會生氣的。老師在講都沒在聽。Zzz...
P.154 費雪的精確性檢定是利用「組合數」,在資料數量僅幾十筆的情況下,仍可正確求出代表比例的差距是否確實有意義的p值。
P.155 由小島寬之所寫的《圖解不再嫌惡統計學》一書幾乎整本都在詳細解說t分佈的推導過程。
P.172 當解釋變數屬於定量變數時就使用回歸分析。
P.172 量化(定量)→數值,例:1024,100。
P.172 質化(定性)→比例,例:0.96,5%,9:4。
P.177 從散佈圖與回歸直線找出「趨勢」。當「代表趨勢之直線與實際資料值之偏差的平方和」為最小時,該直線便視為最合理的趨勢(如圖表3-6)。

終於看到回歸了(斷氣)

P.234 實際上商業活動上,往往很多成果都不是以數字形式來評估大小的,而是像「此人是否曾經來過門市」、「這位會員是否解約」這類以0或1來表示的。因此依狀況不同,有時邏輯回歸可能比多元回歸分析還好用。→這邊用的數學都是大學等級才能懂,所以找個統計學士幫忙比較有效率,且不會得出錯的離譜的結果。
P.236 圖表3-35 依據「廣義線性模型的概念所介紹的各種分析方法

P.344 圖表5-5各統計分析方法所對應的SAS、R、Excel功能。→看來很陽春的統計功具Excel正好達到我需要的上限。

心得感想:
用統計學的框架來找尋統計學的盲點是我讀本書的用意,為何呢?我知道外資用了很多統計學專家設計了近乎完美的交易模組,所以我跟他們比拼最多平手(實務上是輸很大),另外他們設備精良,交易軟體直接掛在券商,券商有特權可架在證交所機房。物理上我已被打好玩的,所以陽關道是走不通,反而要用詭道。統計學的盲點在於每天都必須交易。才能達到統計結果,所以外資必須每天進出,換句話說,不交易就背離統計。那我不交易呢?讓統計繼續累計,直到臨界值,再用選擇權buy side的非對稱式報酬。我覺得我會成為當今主流機械式交易的天敵。
當本書進入z檢定時,我已很吃力了。也從這個分界點知道我的統計知識弱到一整個不行,本書才念到三分之一,或許我不用完全瞭解公式,而是知到意義,至少讀完z檢定知道如何在母體的某一條件分割成二組資料時,是否有明顯的差別。
本書得到最大的心得是知道專家使用方法。當讀到t檢定時我已很吃力,到第12章檢定的多重重要性與其對應處方後,我已對公式處於迷離狀態,後面我已改採懂原理,運算細節跳過。所以專家的用處就在給他條件,他幫你運算出答案。這答案是決策的要素但不是全部。運算部分要拆給專家幫忙運算,一來省腦力、二來以避免運算錯誤,光一個統計學就一堆運用條件的陷阱,這部分還是交由專家吧!自己才能更專注目標。
[2015年10月14日 後記]
我一直感覺我對標準誤差(SE)解釋的有問題,基於善意,還是提醒別認真看本篇會比較好。我還要再多找幾本統計學的書來看,尤其作者說他介紹的是五十年前的知識,現代最新的統計學完全沒提到,五十年…,人類都從電話升級用智慧手機了。
書籍資料:
書名:統計學,最強的商業武器:實踐篇
原名:Statistics, literacy for the next generation: Professional
作者:西內 啟
原文作者:西內 啟
譯者:陳亦苓
出版社:悅知文化
出版日期:2015/08/24
閱讀價值:中
ISBN:9789865617288
目錄:
序章商業活動與統計學之間的連結
01 商業與統計學之間為何存在著鴻溝
02 「掌握」、「預測」,以及「洞悉」的統計學
第 1 章統計學的實踐,就從重新思考基本觀念開始
──「平均」及「比例」的本質
03 「洞悉」型統計學的三項必要知識
04 「平均值」其實很深奧
05 平均值為何能夠掌握真相?
06 標準差所呈現的「概略資料範圍」
第 2 章統計學之所以「最強」的另一個理由
──標準誤差及假設檢定
07 介於急驚風與慢郎中之間的「最強」思維
08 「誤差範圍」與資料量的關係
09 為貧乏言論畫上休止符的假設檢定
10 用z檢定來駁斥急驚風
11 用於少量資料的t檢定與費雪的精確性檢定
12 檢定的多重性與其對應處方
第 3 章堪稱洞悉之王道的各種分析工具
──多元回歸分析與邏輯回歸
13 統計學的王道──回歸分析
14 如何求出迴歸直線?
15 一次分析多個解釋變數的多元回歸分析
16 邏輯回歸與對數比值
17 回歸模型的總結與補充
18 實用的迴歸模型應用方法──輸入層面
19 實用的迴歸模型應用方法──輸出層面
第 4 章在資料背後隱藏了「什麼」
──因素分析與聚類分析
20 心理學家所開發的因素分析有何用途
21 具體而言,因素分析到底能做些什麼?
22 聚類分析的基本觀念
23 k-平均演算法(k-means)的聚類分析
終章統計方法總整理與使用順序介紹
24 本書總結
25 商業應用時的分析順序
26 無法透過本書獲得的三種知識
數學公式的補充說明
補充01:偏差的絕對值與中位數
補充02:偏差的平方與平均值
補充03:平均值與比例的標準誤差
補充04:變異數與無偏變異數
補充05:常態分佈的數學特性
補充06:中央極限定理
補充07:切比雪夫不等式
補充08:針對平均值與比例之差距的z檢定
補充09:卡方分佈與t分佈的關係
補充10:費雪的精確性檢定
補充11: z檢定與卡方檢定
補充12:邦弗朗尼校正
補充13:簡單回歸分析
補充14:簡單回歸分析與t檢定的關係
補充15:多元回歸分析
補充16:比值比
補充17:檢定力與樣本數規劃
沒有留言:
張貼留言